
Celebrity Facial Recongition
By Stephanie Fissel, Beza Gashe, & Claire Yoon
Introduction
Facial recognition technology (FRT) relies on massive datasets to “learn” faces to accurately identify or verify the identity of a person. It captures, analyzes, and compares patterns based on a person’s facial features. Facial biometrics continues to be the preferred biometric benchmark above all other methods because it’s easy to deploy and implement, does not require any physical interaction with the end-user, and is very quick.
Facial recognition is now implemented across many industries because of its wide applicability, benefits, and convenience. Many issues, small and large, that we once faced a decade ago are being solved thanks to this technology.
For example, it can be used to:
- Help find missing people and identify perpetrators
- Protect businesses against theft
- Improve medical treatment
- Strengthen security measures in banks and airports
- Unlock sensitive information on mobile devices
- Make shopping more efficient
- Drastically reduce human touchpoints
- Help organize photos
ALGORITHMIC BIAS
It's important to recognize the limitations reflected in these algorithms, particularly for identifying women, Black, and Asian individuals. Graduate student Joy Buolamwini coined the term “coded gaze” in her TED talk, describing algorithmic bias resulting in “exclusionary experiences and discriminatory practices.” As FRT continues advancing, society must work towards diminishing these biases and improving identification of all faces regardless of race or gender.
Joy Buolamwini's TED Talk
QUESTION
Can we create multiple machine learning models that accurately identify and detect the correct person from a particular group of people with similarities in their appearances?
CNN MODEL PROCESS
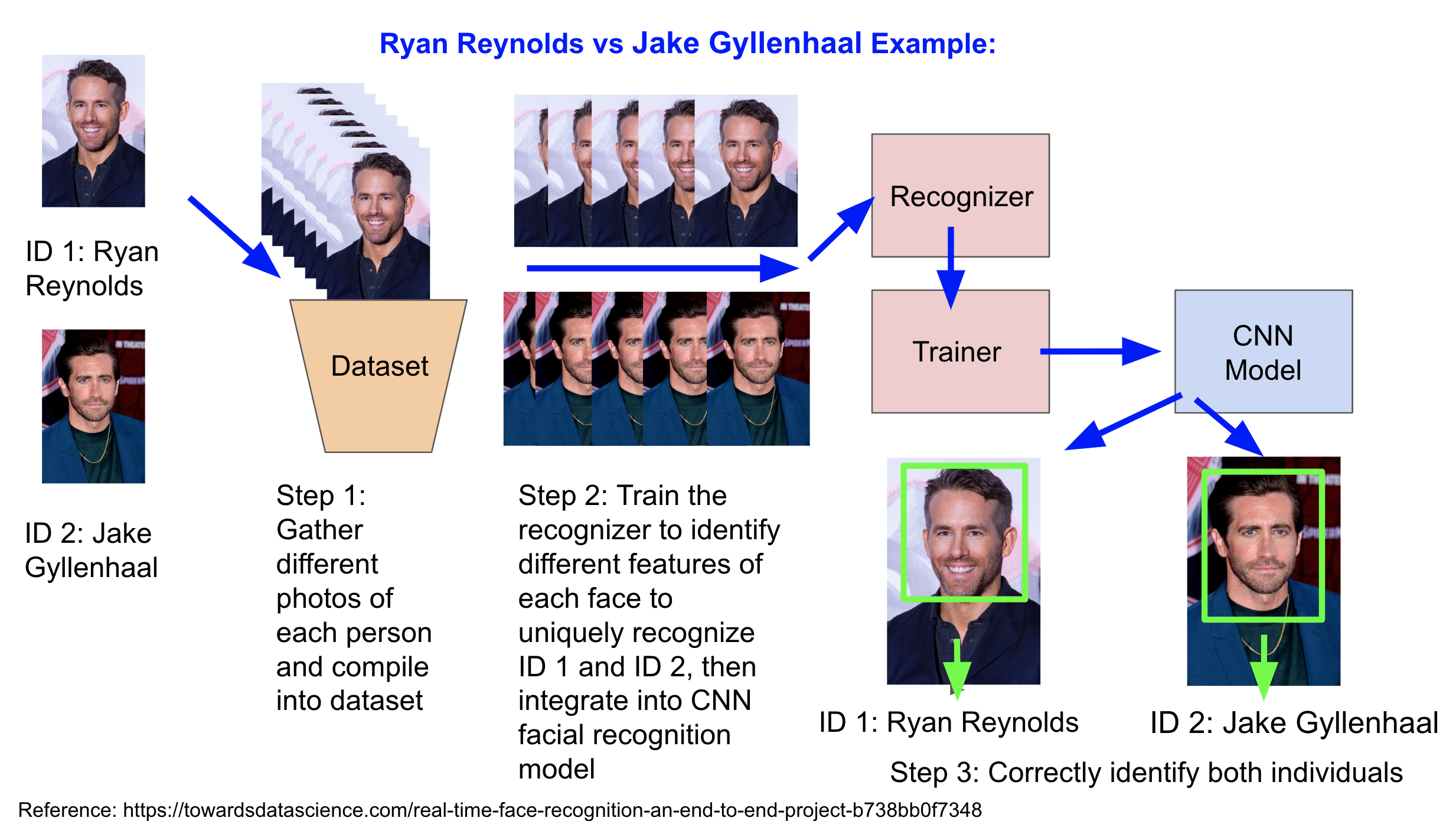
Exploratory Data Analysis
Datasets used are images collected from the Internet through either web scraping or web crawling
- Each three-person model was trained with 360 images and validated with 120 images
+ Training: 120 images per person
+ Validating: 40 images per person
Methods
Methods for data selection, data collection, and model implementation
- Web crawling groups were split between male and female and amongst three racial groups (White, Black, Asian) for total of six groups
- Selected celebrities were chosen because of similar ages and facial appearances
DATA COLLECTION:
WEB SCRAPING
Web scraping is the automated process of collecting structured information from the Internet. Extracts and duplicated data from any page it accesses.
How it works:
1. Identify target URLs
2. Choose the right proxies
3. Send requests to the URL
4. Extract HTML code
5. Parse data string
6. Convert and save data
FEATURE ENGINEERING
To improve accuracy and account for different image types, colors, and backgrounds, we tried to augment and normalize the web scraped images by: ✽ Method only used for White Male Celebrities because time consuming and extensive computing resource requirement
- converting to black and white
- cropping just the head
- only using better resolution images

DATA COLLECTION:
WEB CRAWLING
Web crawling is used by search engines to scan the Internet for pages according to the keywords you input and remember them through indexing for later use in search results. Navigates and reads pages for indexing.
How it works:
1. Get seed set of URLs
2. Go to first URL
3. Retrieve page's data
4. Analyze content and find links
5. Add links to URL frontier
6. Remember the visited URL and move to next
✽ Used open source library (bing-image-downloader) for this method for all groups
CNN MODEL
- Batch Number: 32
+ Batch size means number of images used to train a single forward and backward pass
+ Picked 32 because it's considered a good default value and helps compute faster (taking full advantage of GPU processor)
- Epoch Number: 50 → 15 → 10
+ Originally set at 50 but didn't find a pattern and model's loss didn't consistently decrease
+ To improve, set at 15 but after 10 iterations there was overfitting issue
+ Eventually set at 10 as ideal epoch value
- Transfer Learning
+ Technique of using a model to solve another related task
+ Since training a network model requires a lot of data, it's common to use different network model weights to reduce training time
+ Advantage is that people can train the last layer using a smaller dataset
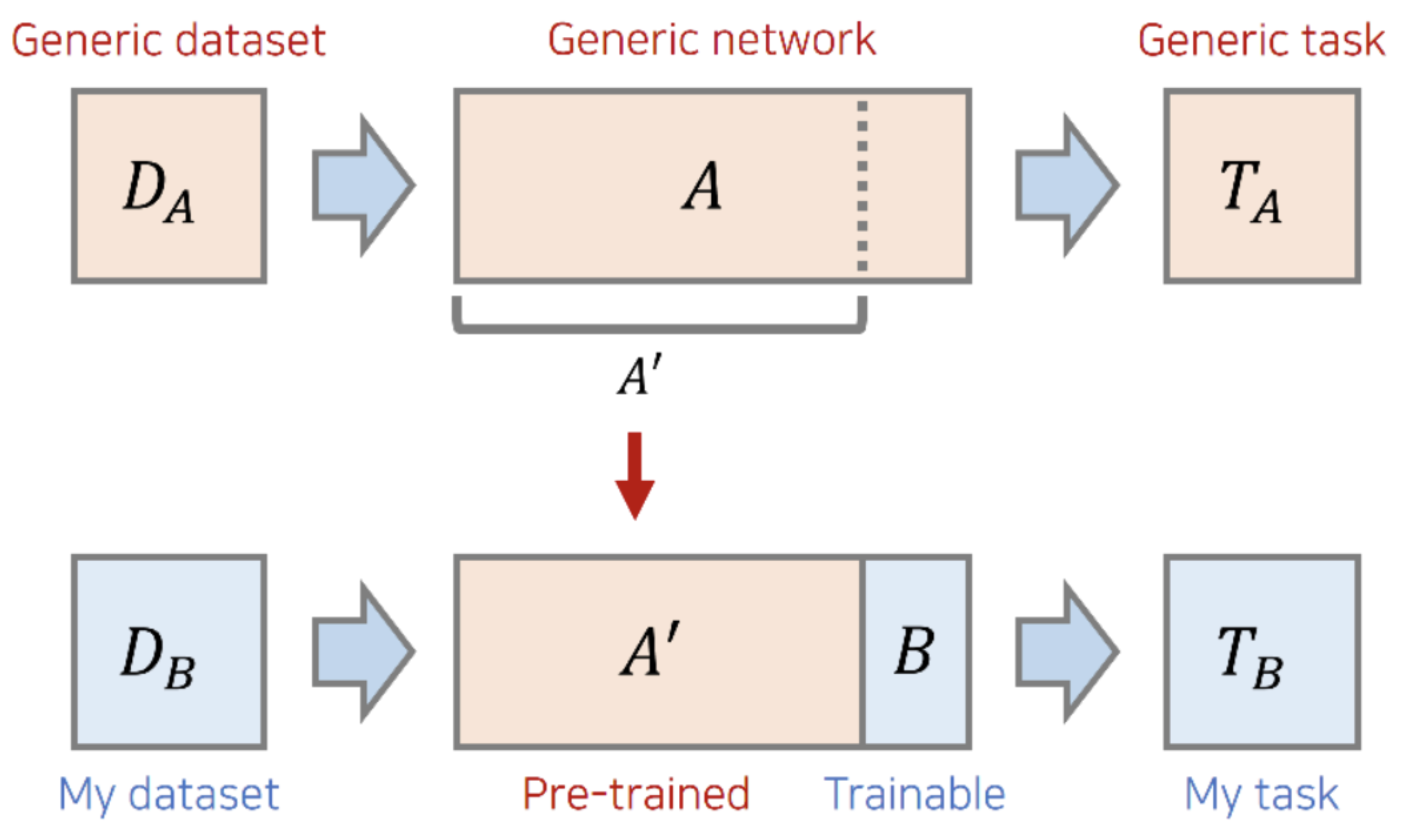
- Our Transfer Learning Process with PyTorch
+ Step 1: Load the Data
- Load data from folder with torchvision.dataset
- Transform images to match network requirements (resize, horizontal flip, normalize, convert to tensor)
+ Step 2: Define Model
- Use torchvision.models to load resnet34 with pre-trained weight set to TRUE
- Use CrossEntropyLoss for multi-class loss function and optimizer (SGD: Stochastic Gradient Descent) with learning rate of 0.001 and momentum of 0.9
+ Step 3: Train and Test Model
- Train and evaluate model with epoch of 10
+ Step 4: Results
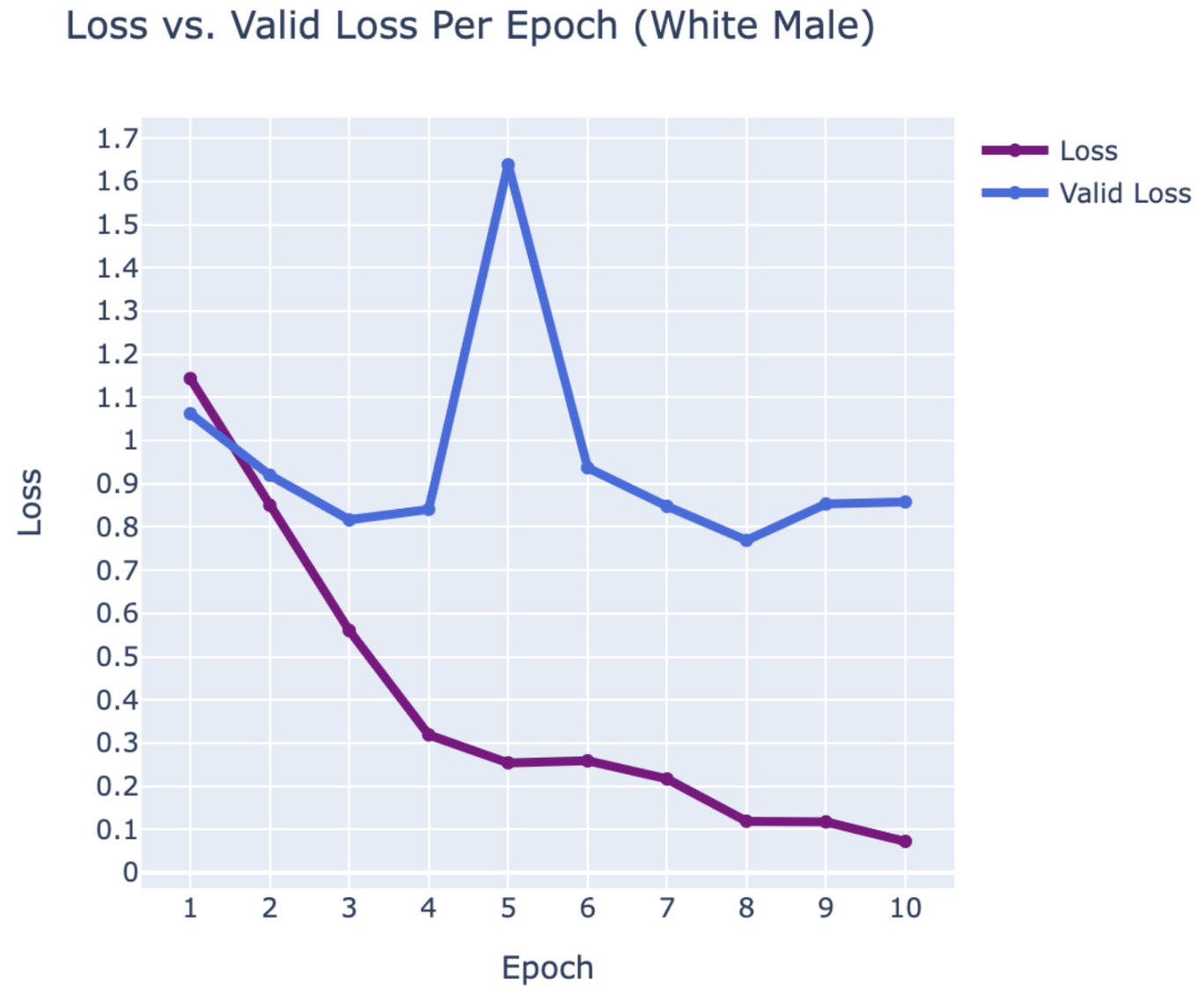
- Review results by comparing training loss with validation loss
Results & Evaluation
Initially started with data from web scraping but because of limitations and curiousity to evaluate more data, we mostly used web crawling
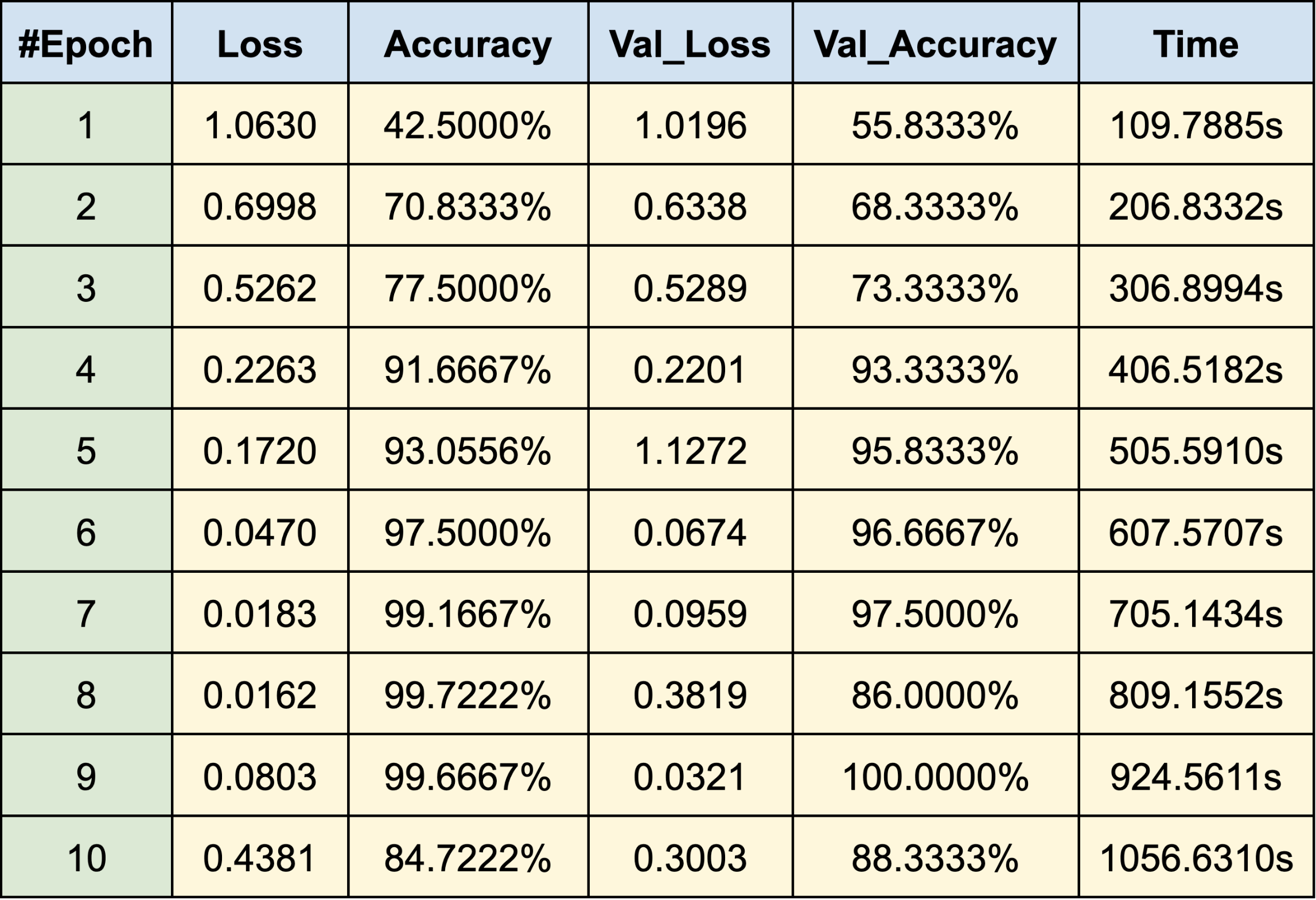
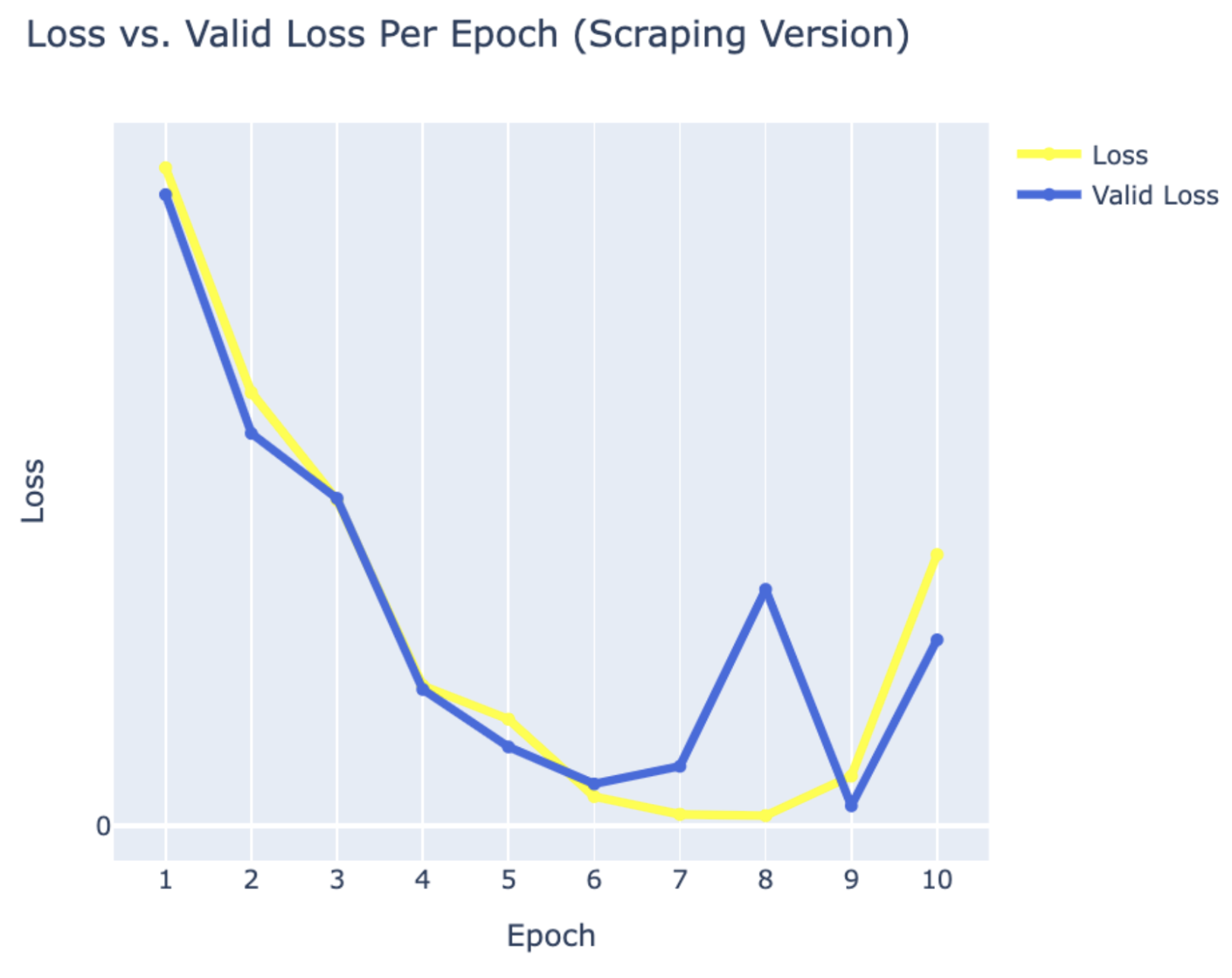
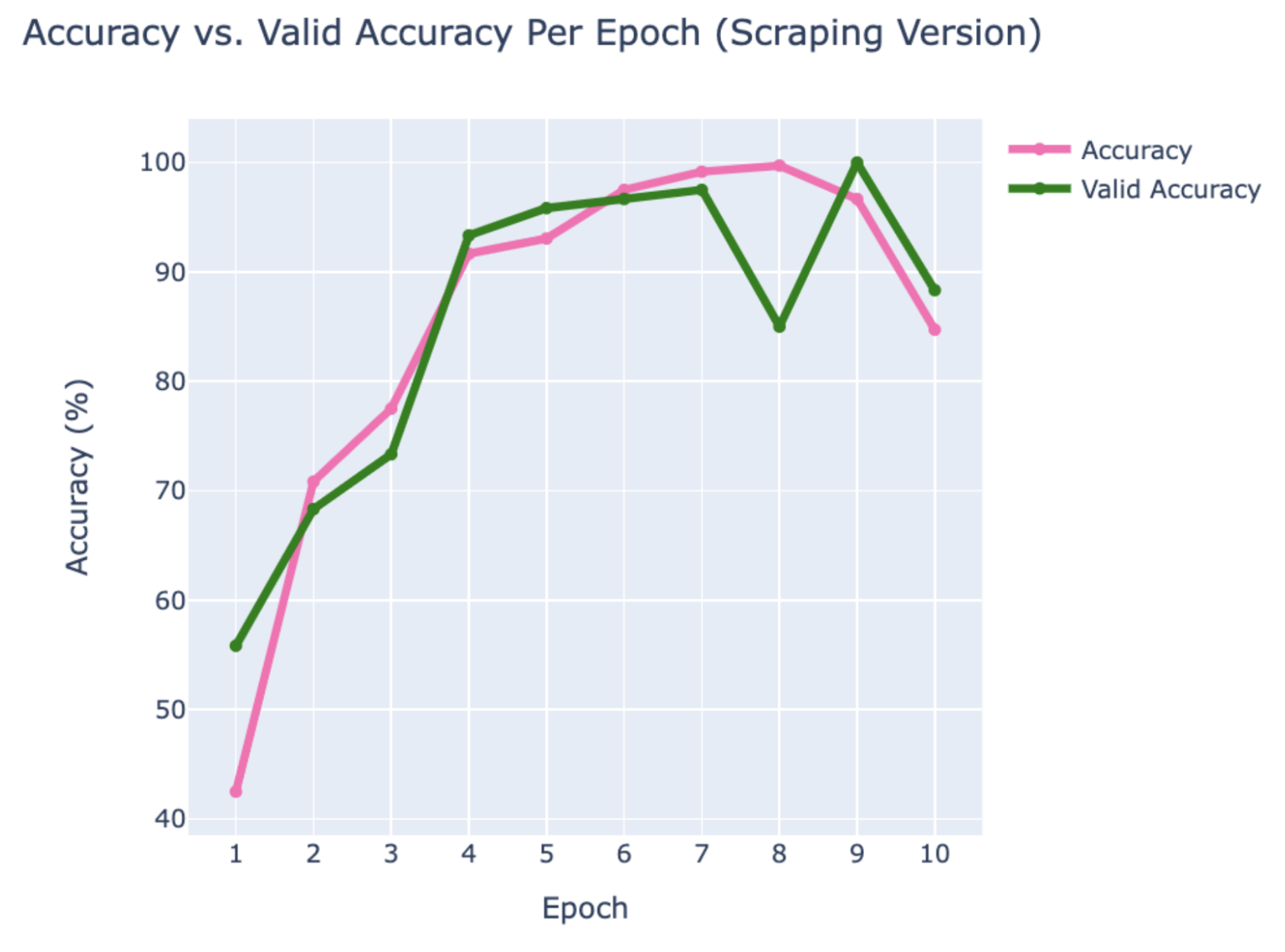
WEB SCRAPING:
WHITE MALE
- Hugh Jackman
- Jake Gyllenhaal
- Ryan Reynolds



RESULTS
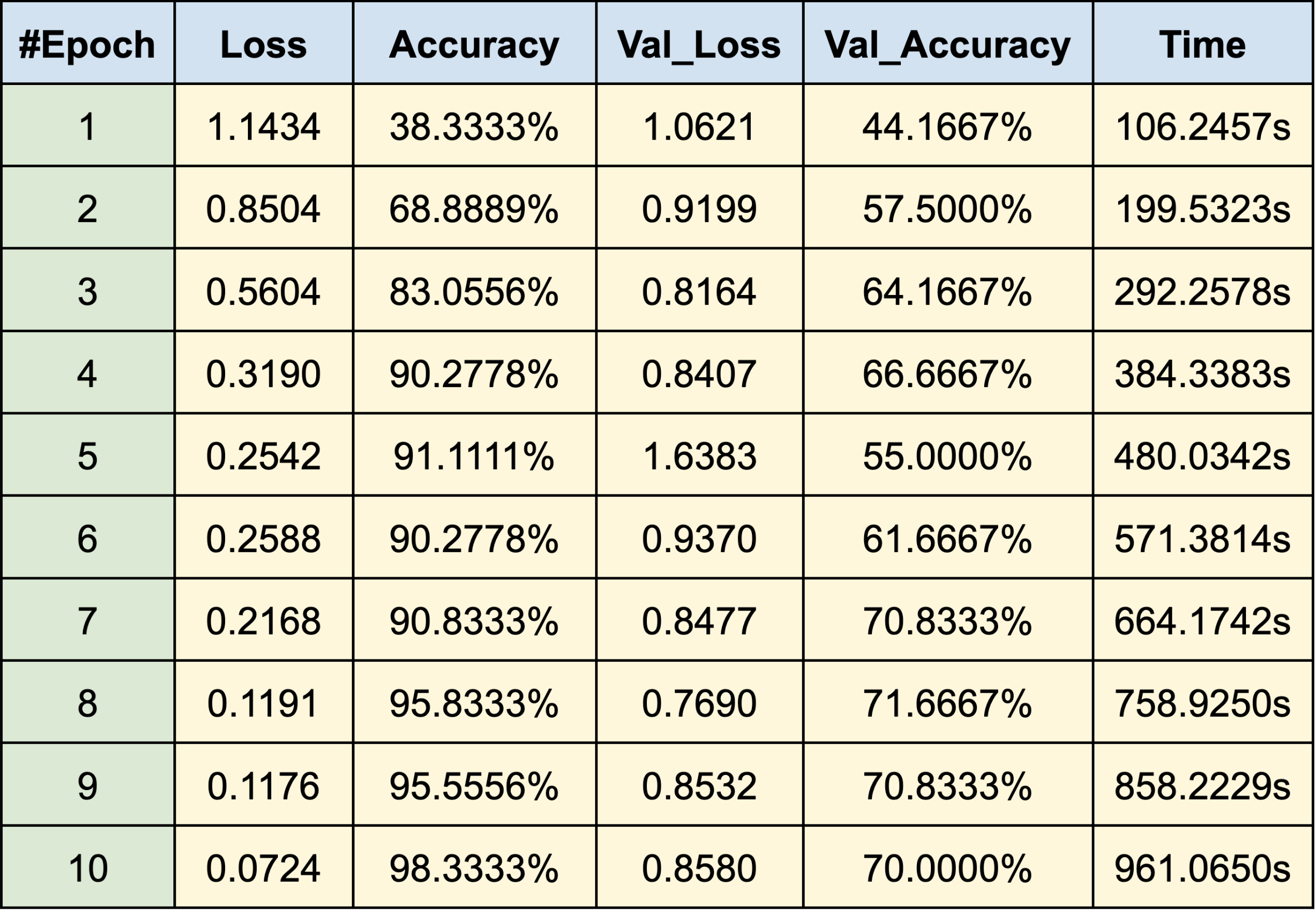
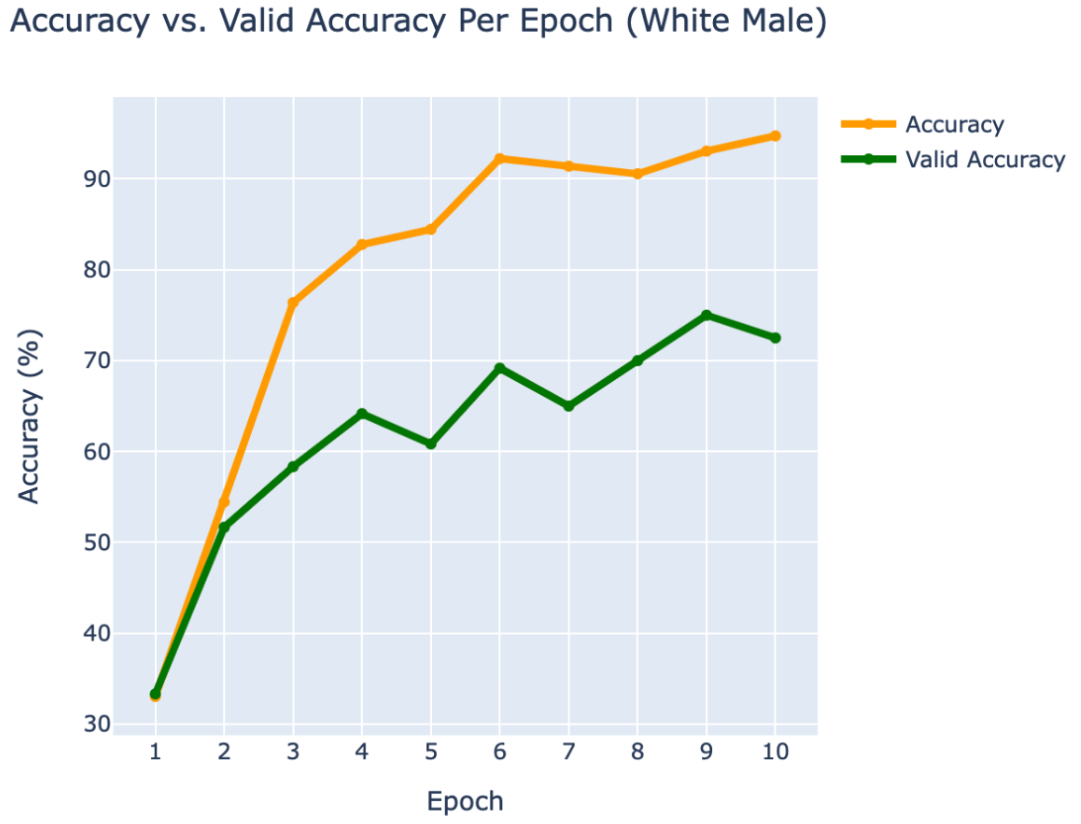
WEB CRAWLING:
WHITE MALE
- Hugh Jackman
- Jake Gyllenhaal
- Ryan Reynolds
RESULTS
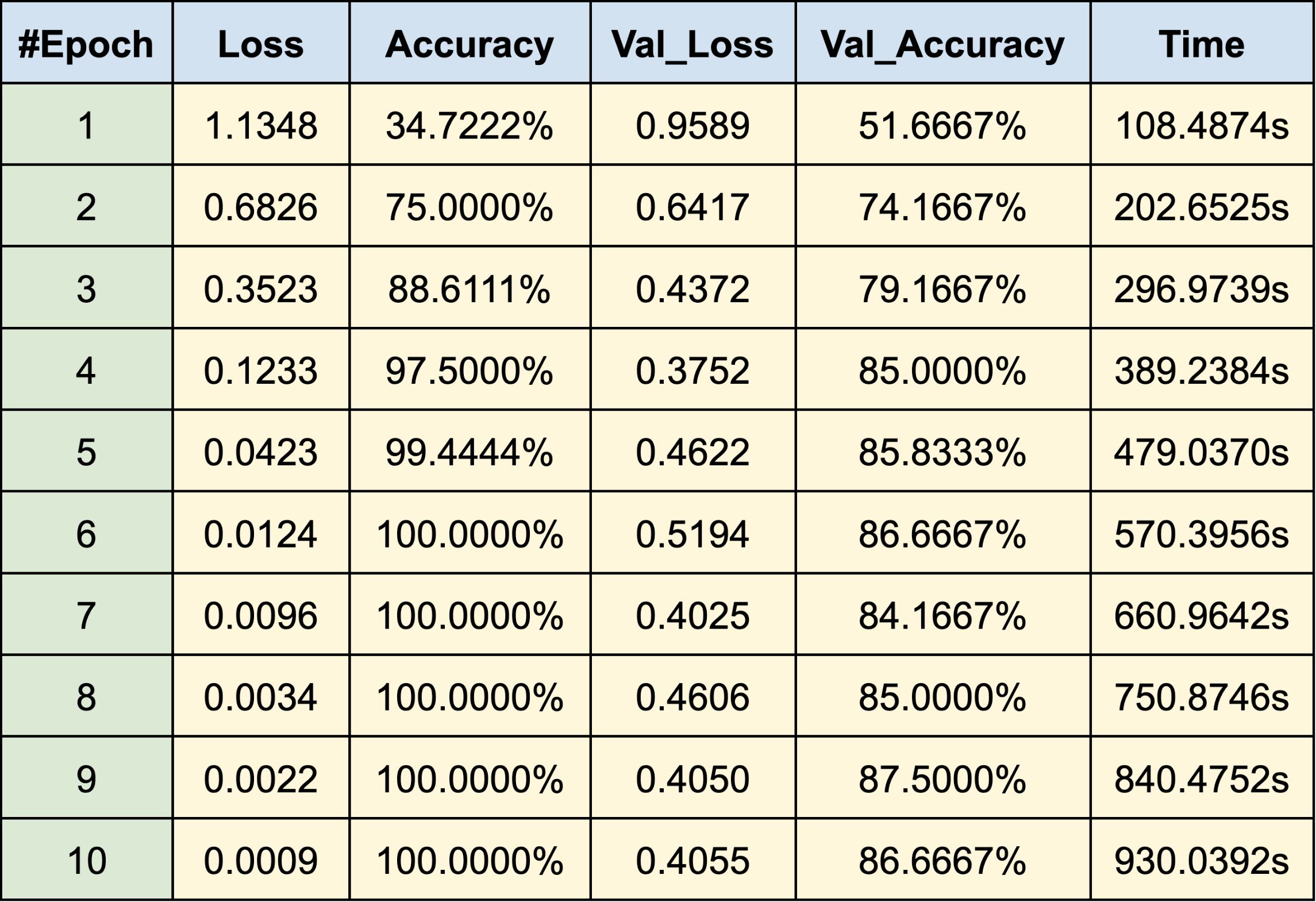
WEB CRAWLING:
WHITE FEMALE
- Lucy Hale
- Mila Kunis
- Sarah Hyland



RESULTS
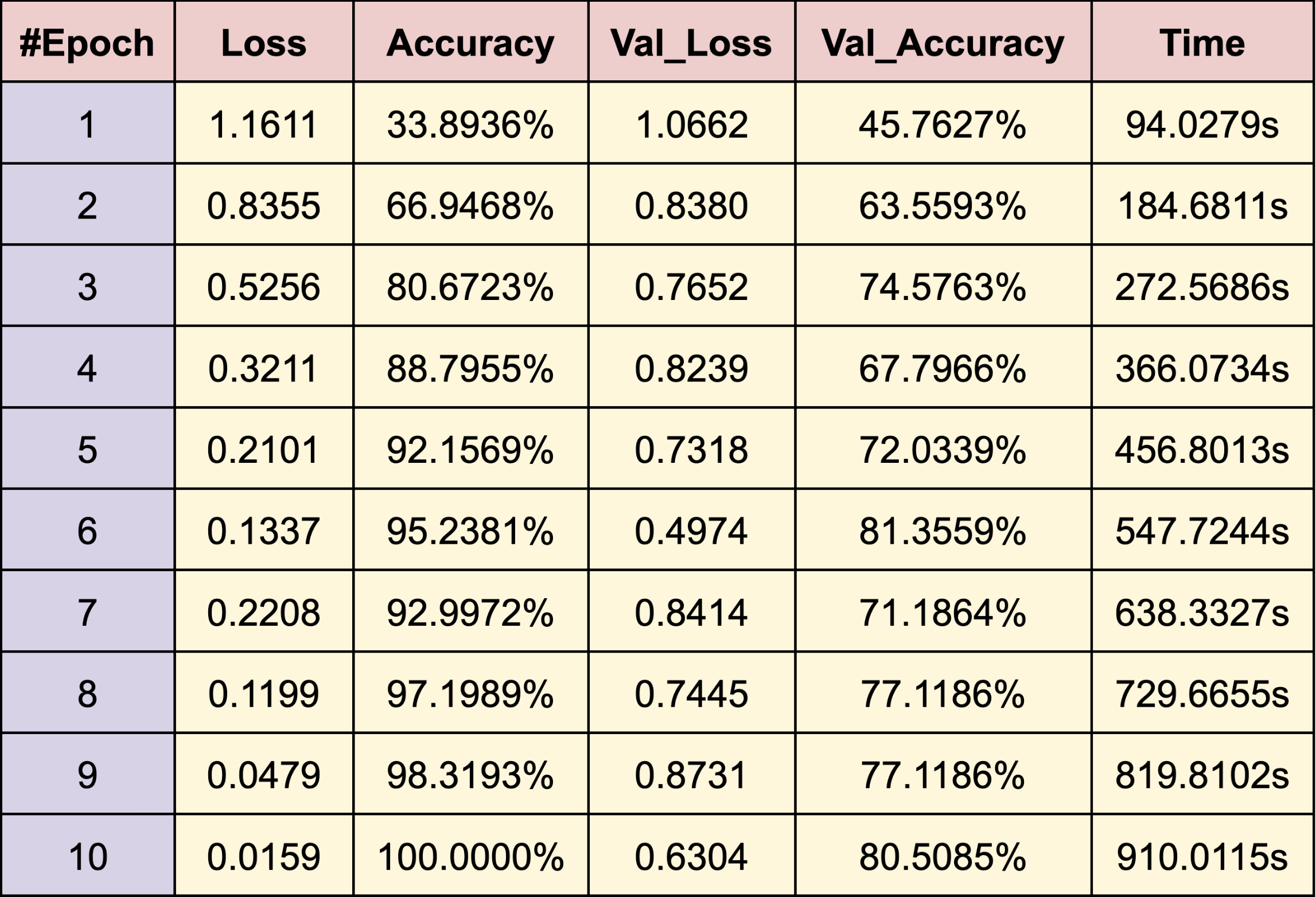
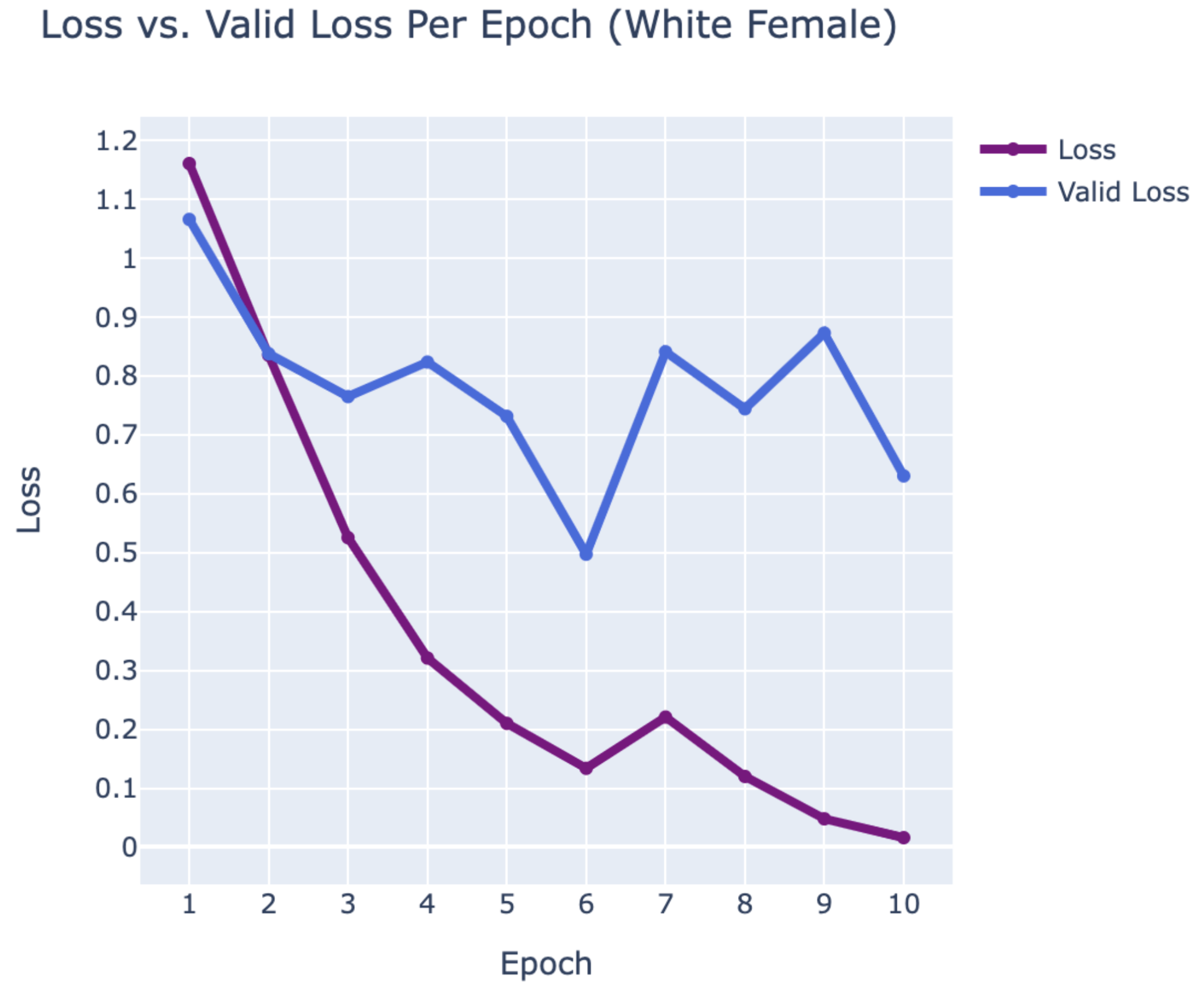
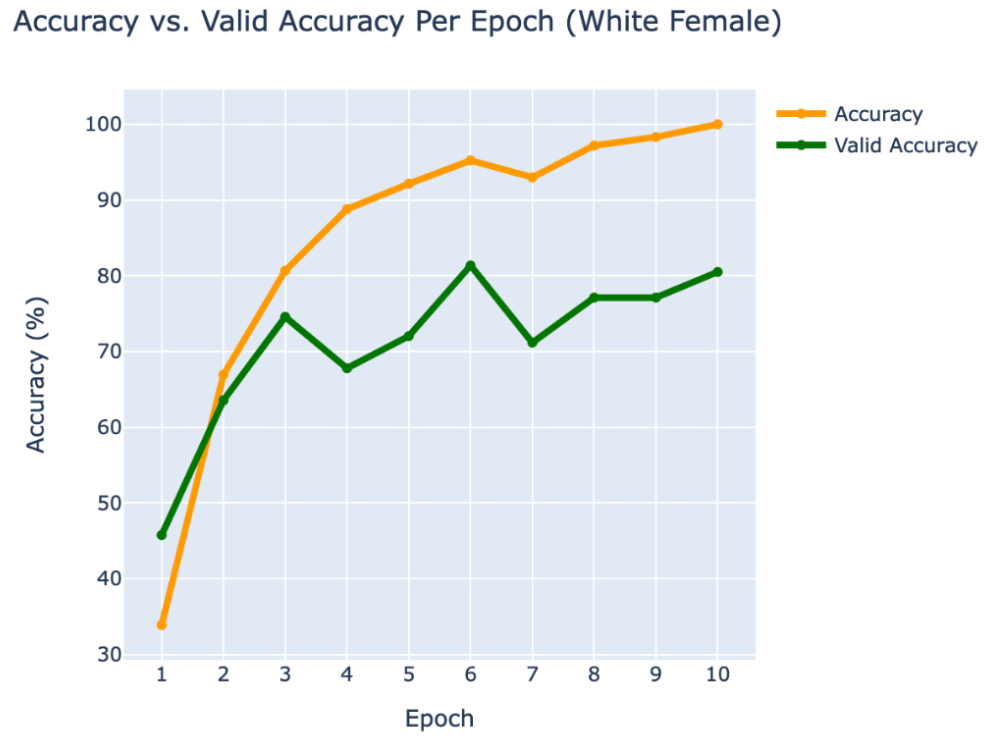
WEB CRAWLING:
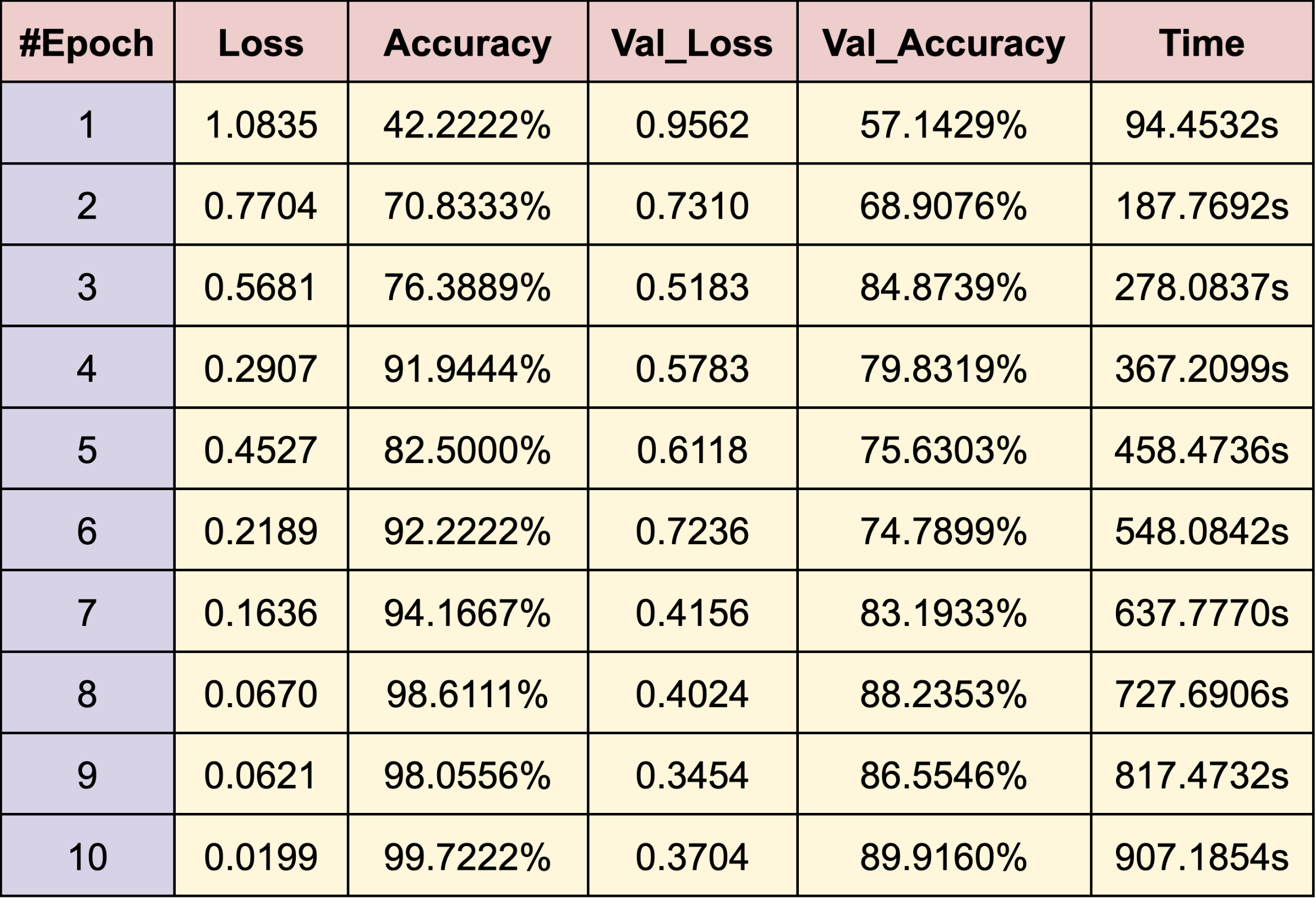
BLACK MALE
- Danny Glover
- Denzel Washington
- Morgan Freeman



RESULTS
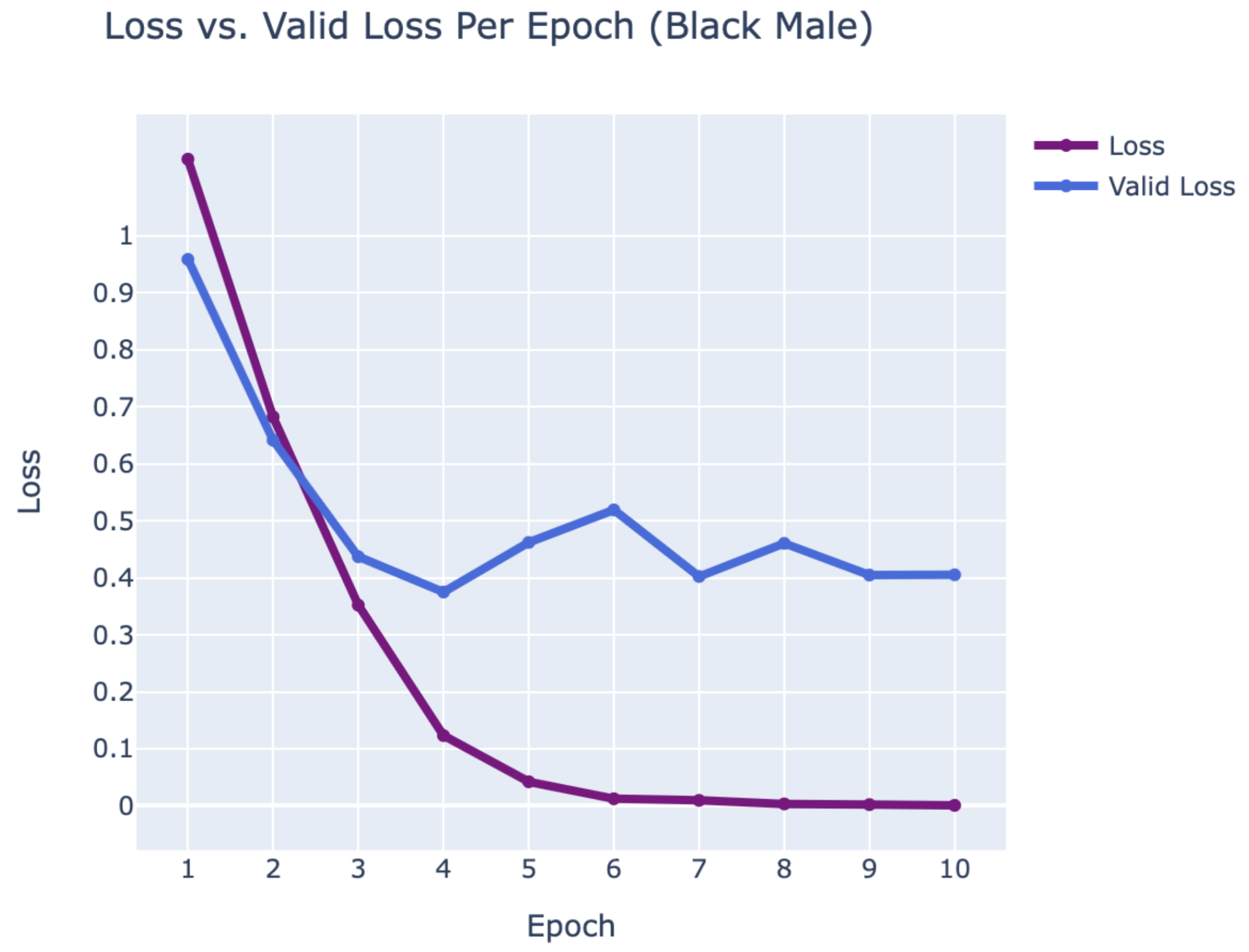
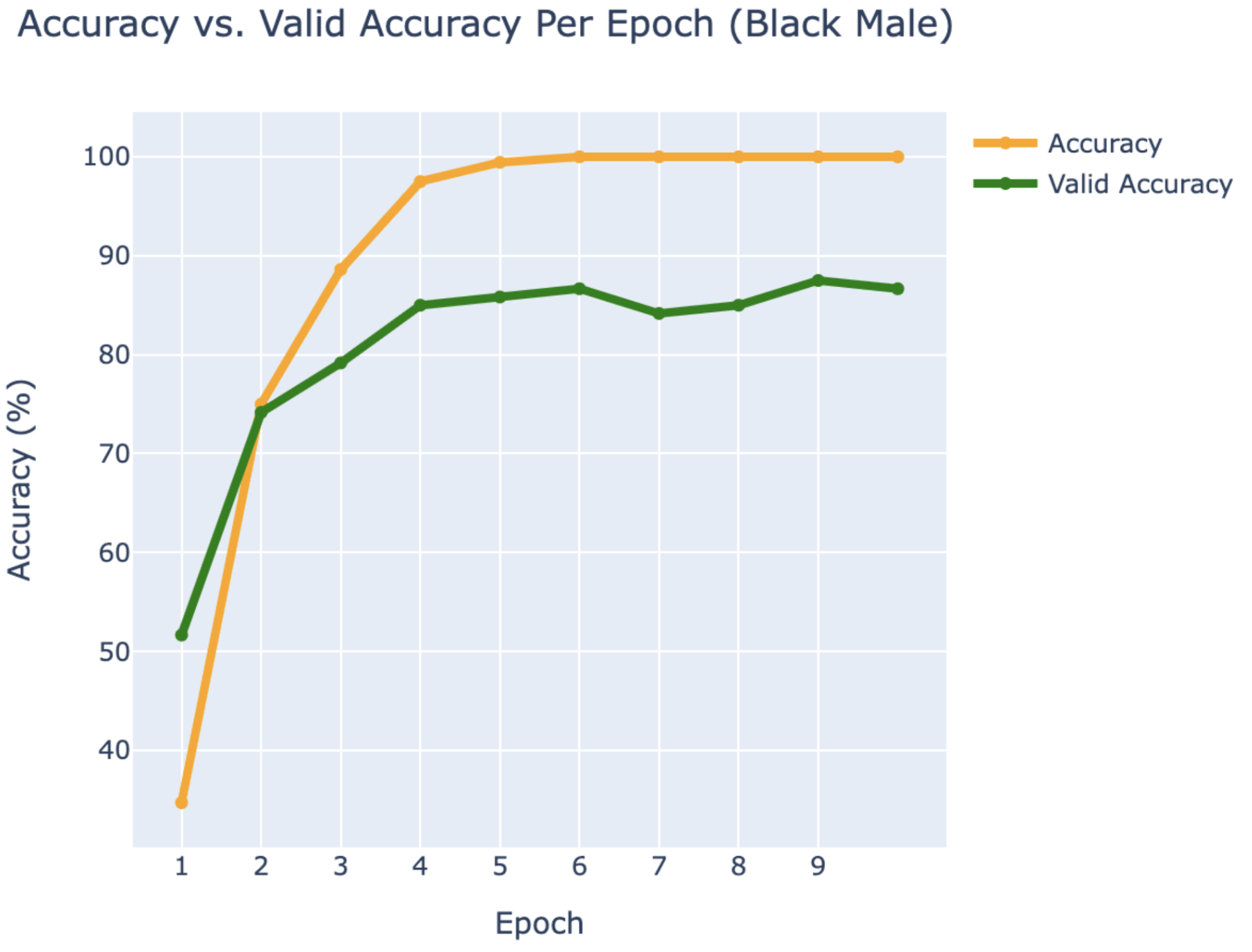
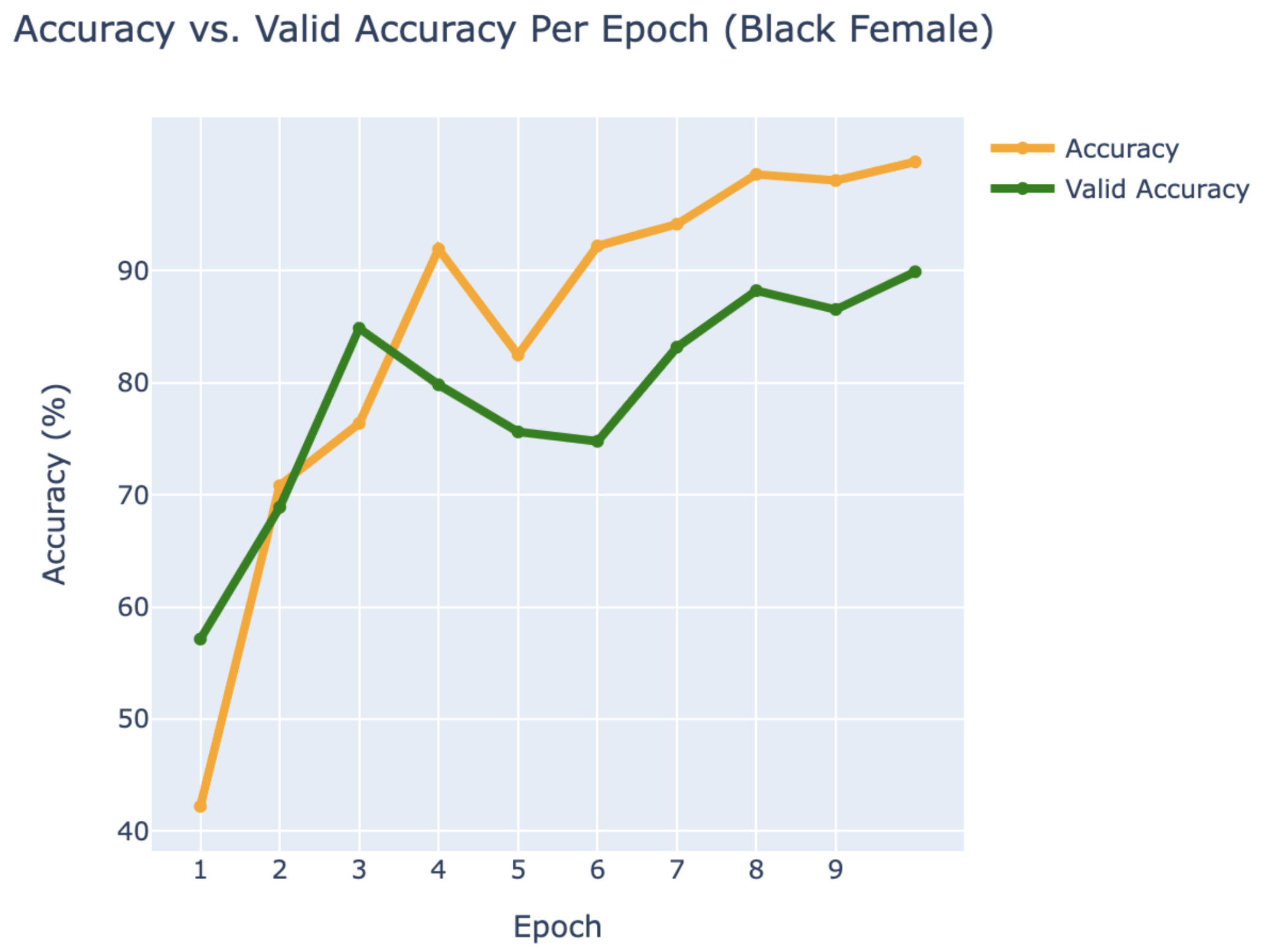
WEB CRAWLING:
BLACK FEMALE
- Alicia Keys
- Jordin Sparks
- Queen Latifah



RESULTS
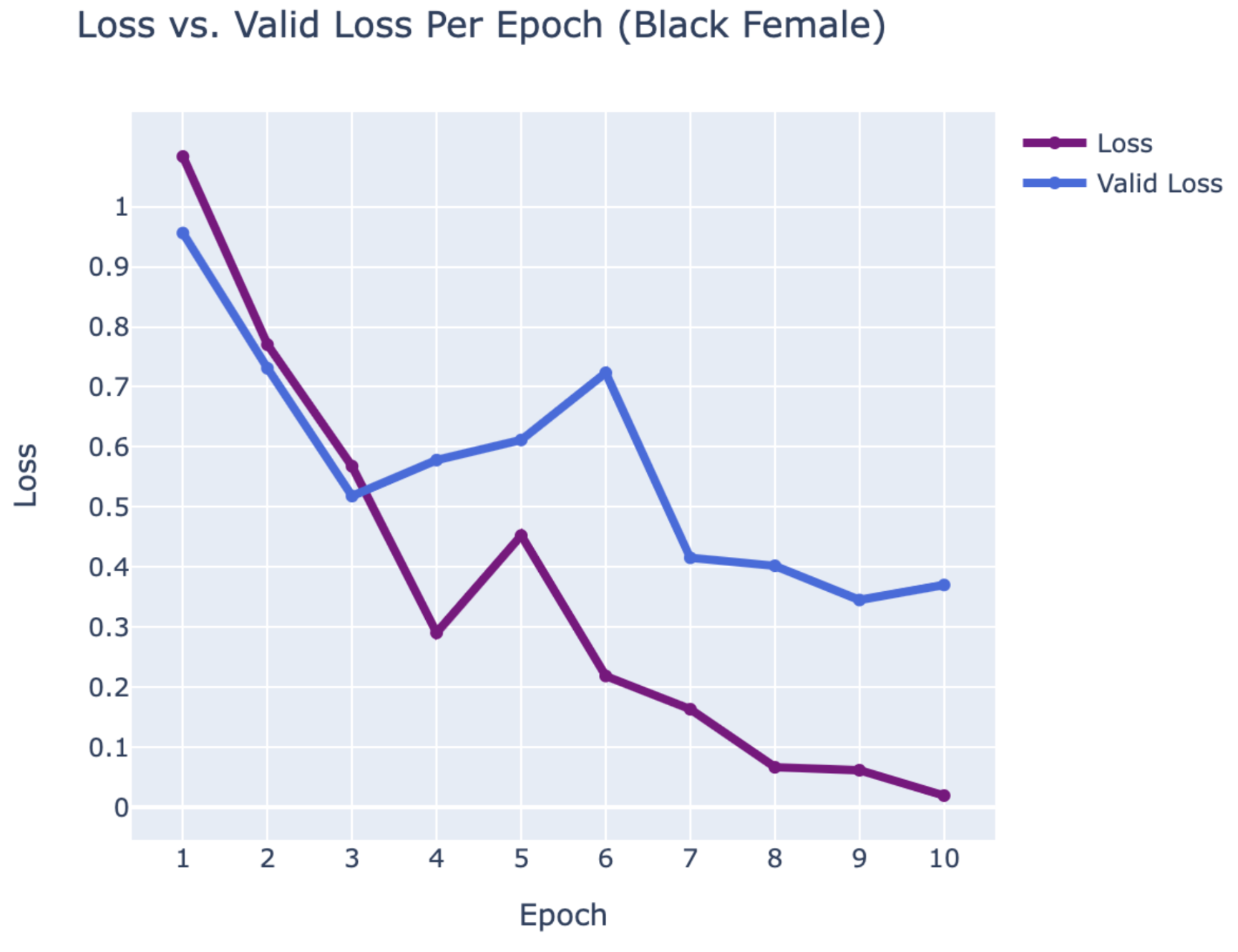
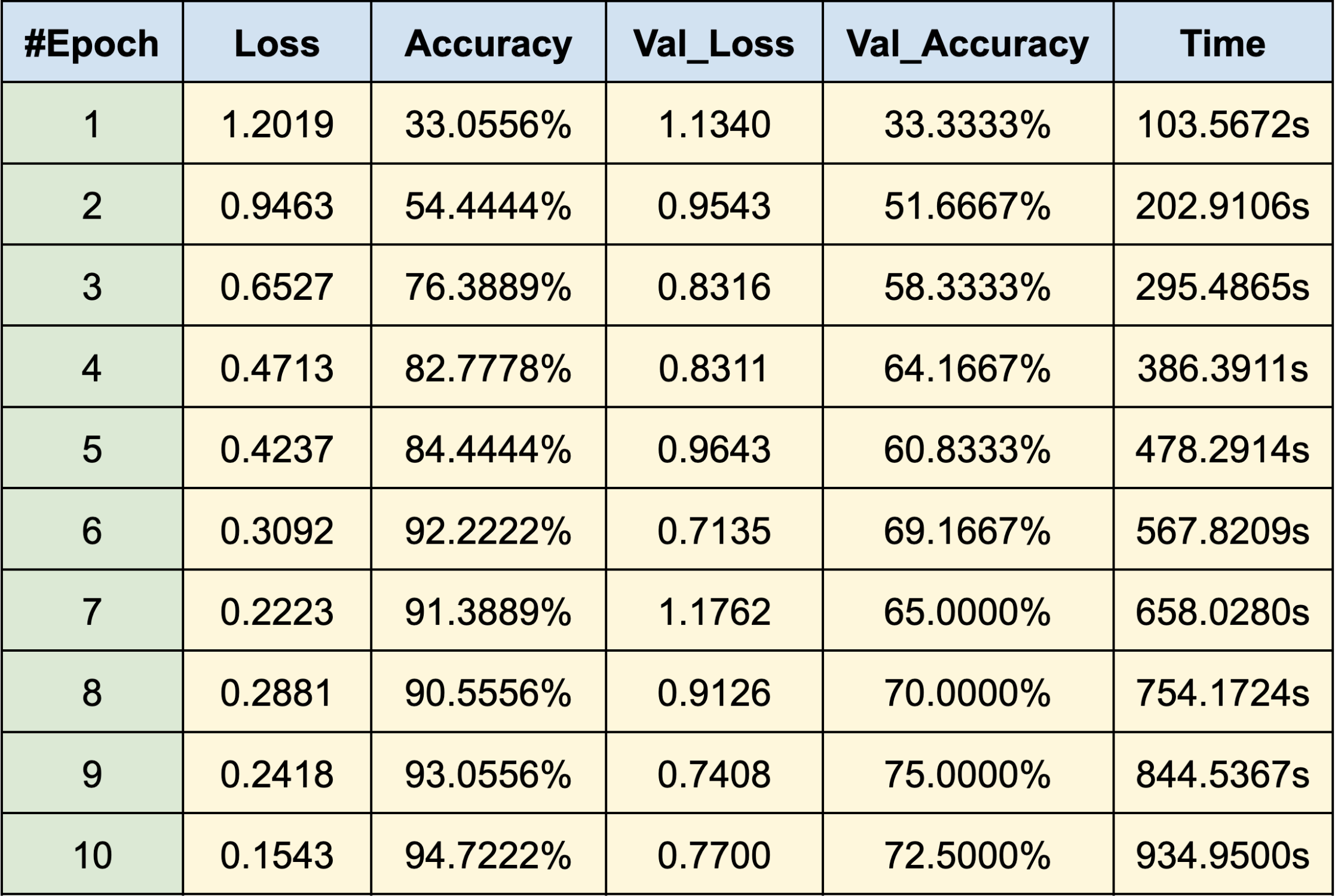
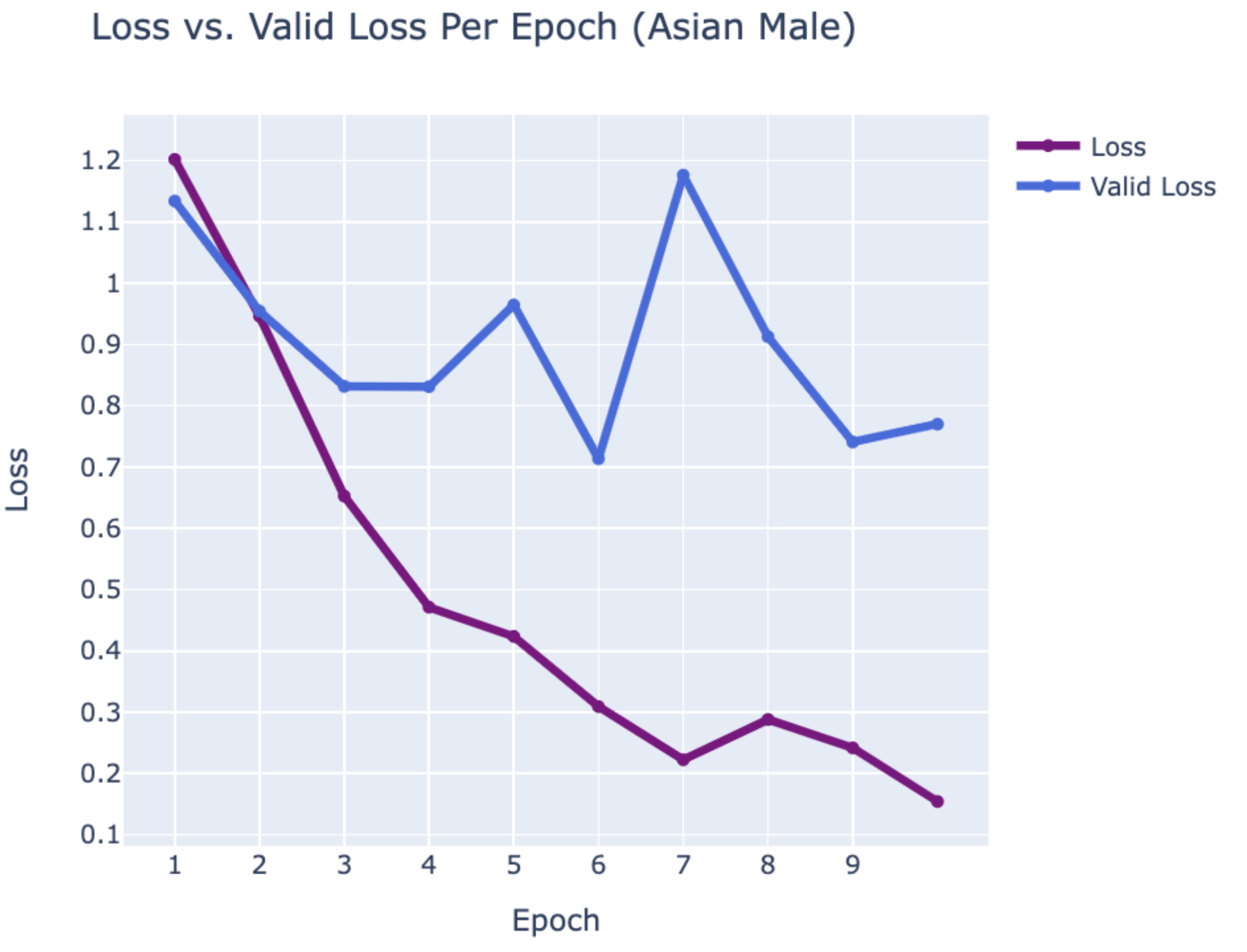
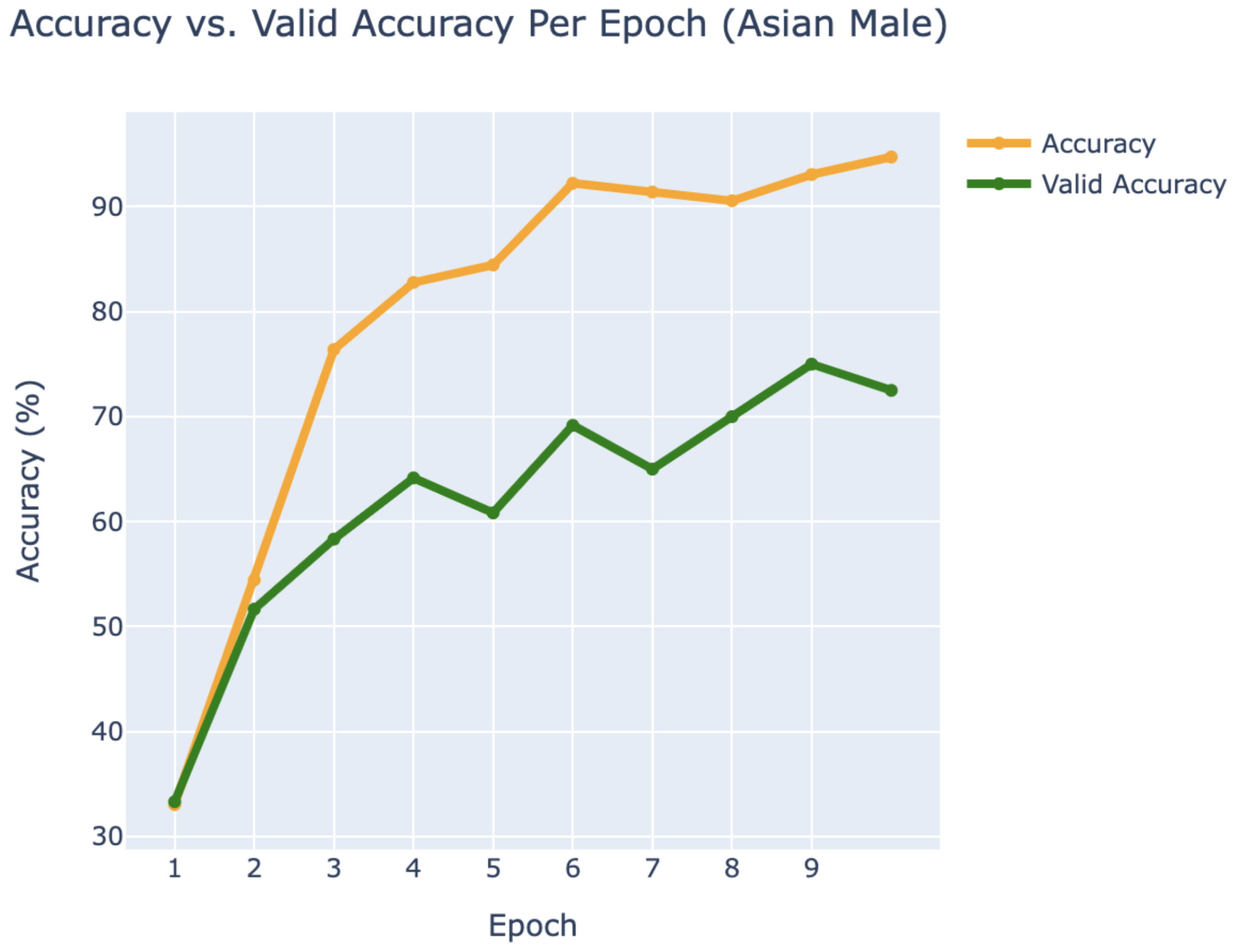
WEB CRAWLING:
ASIAN MALE
- BTS:
- Jimin
- Jung Kook
- V



RESULTS
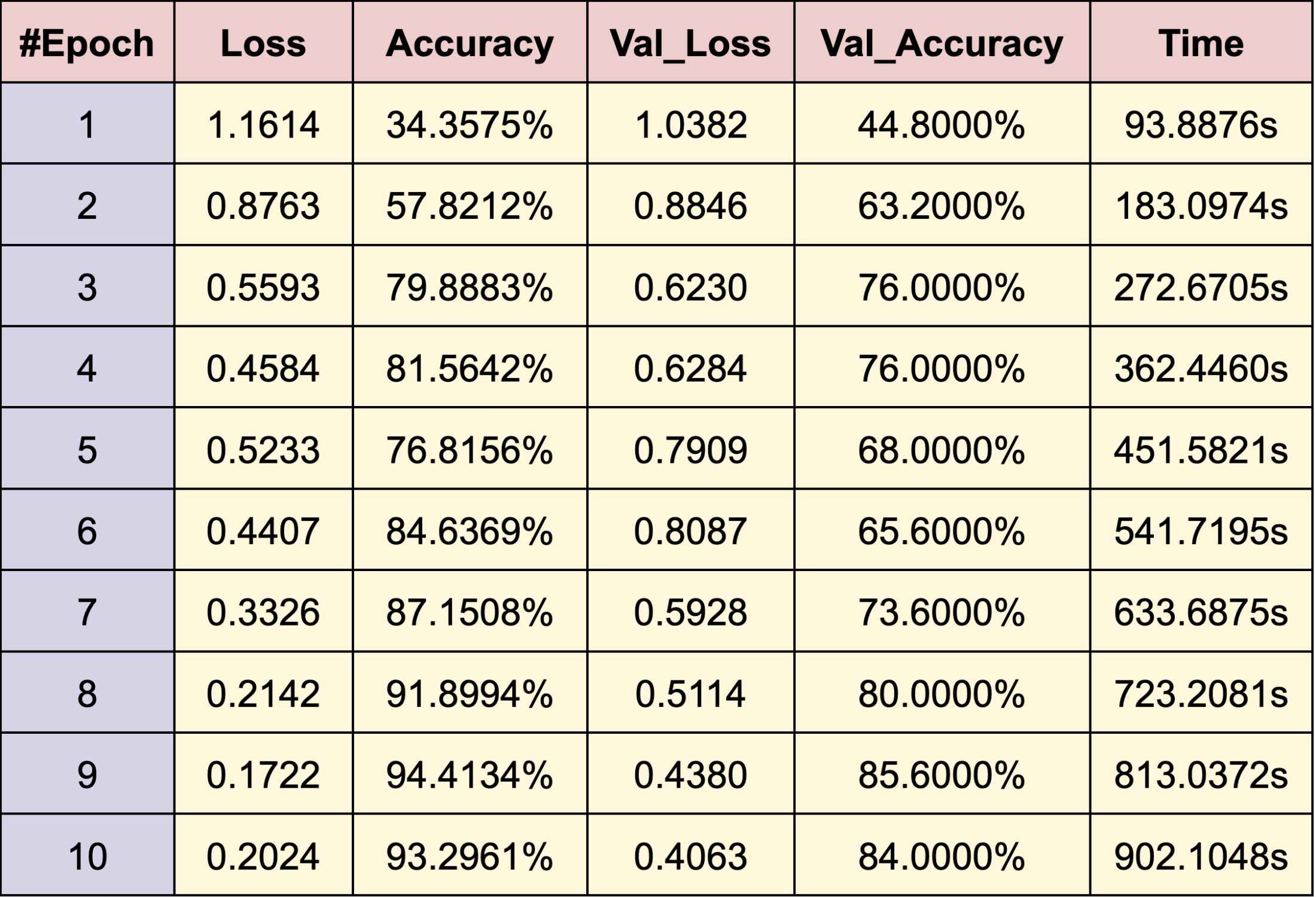
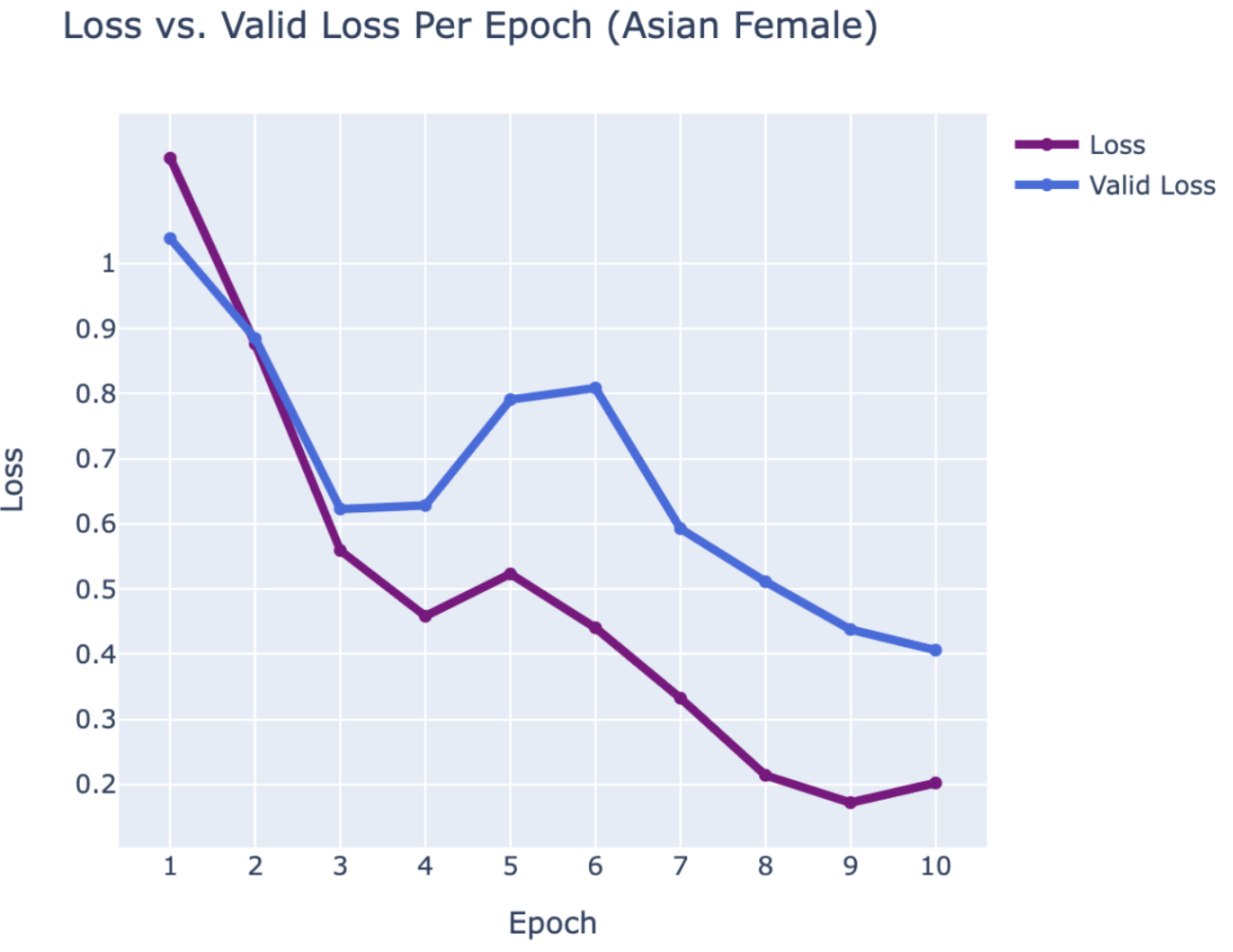
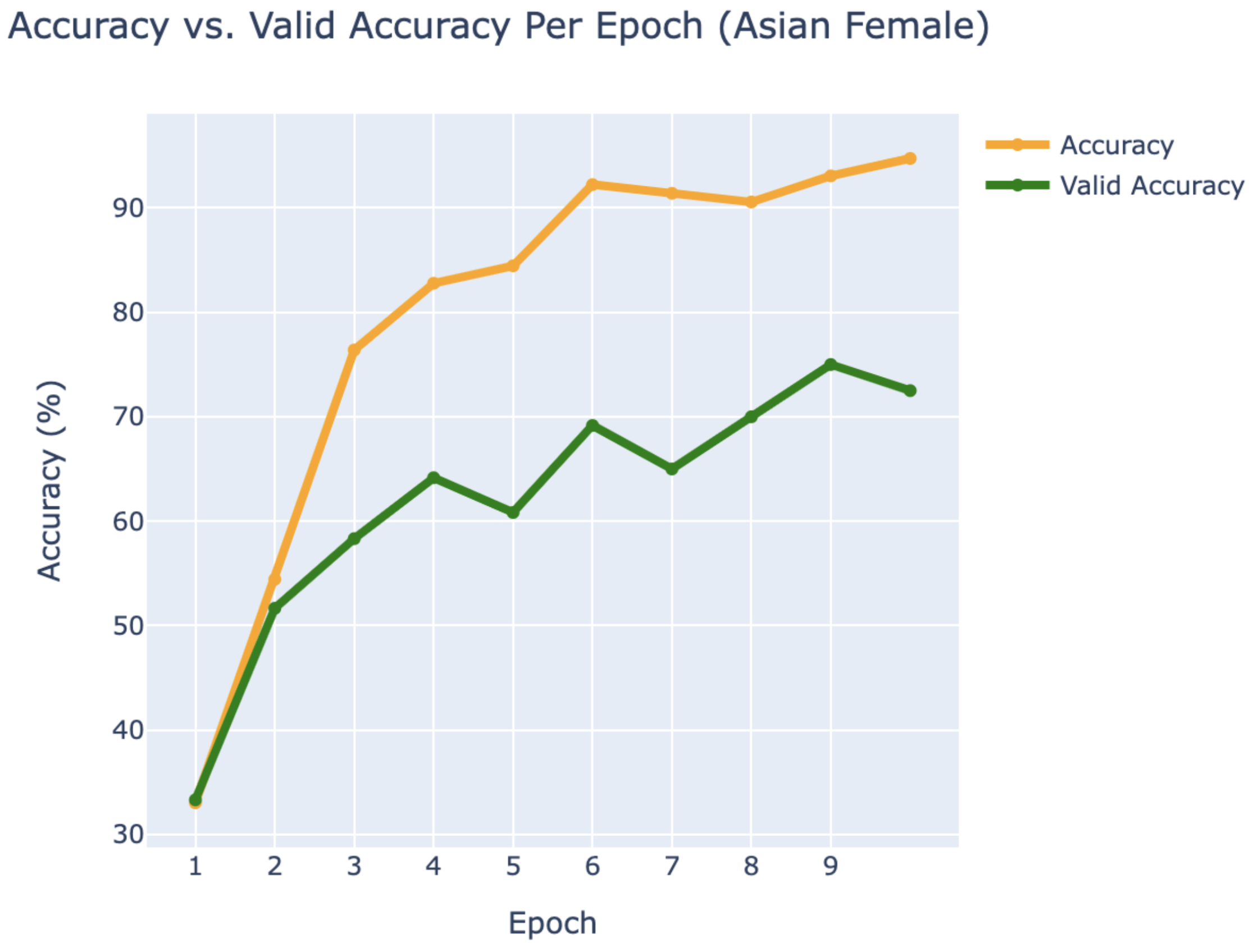
WEB CRAWLING:
ASIAN FEMALE
- Blackpink:
- Jennie
- Jisoo
- Rosé



RESULTS
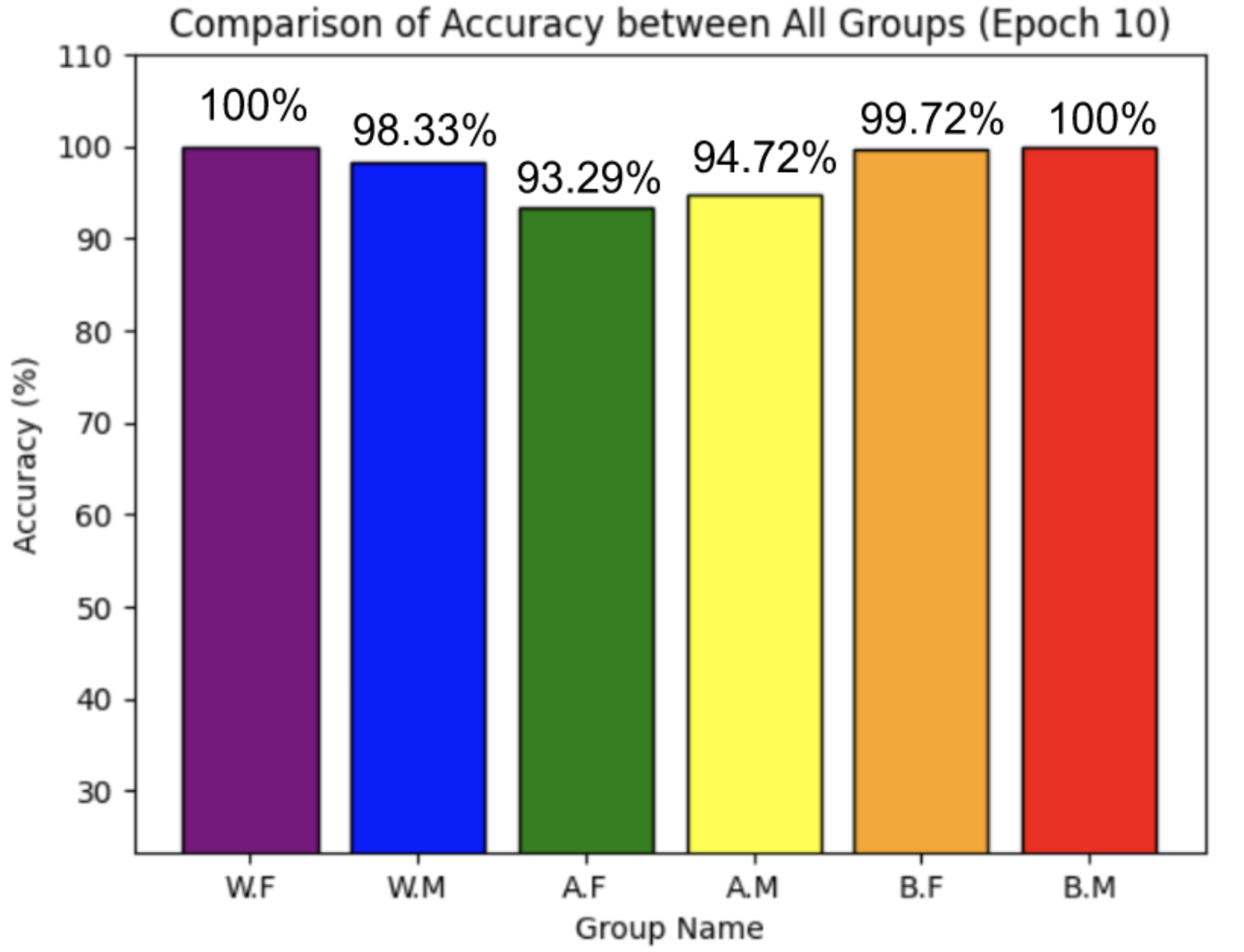
MODEL COMPARISON
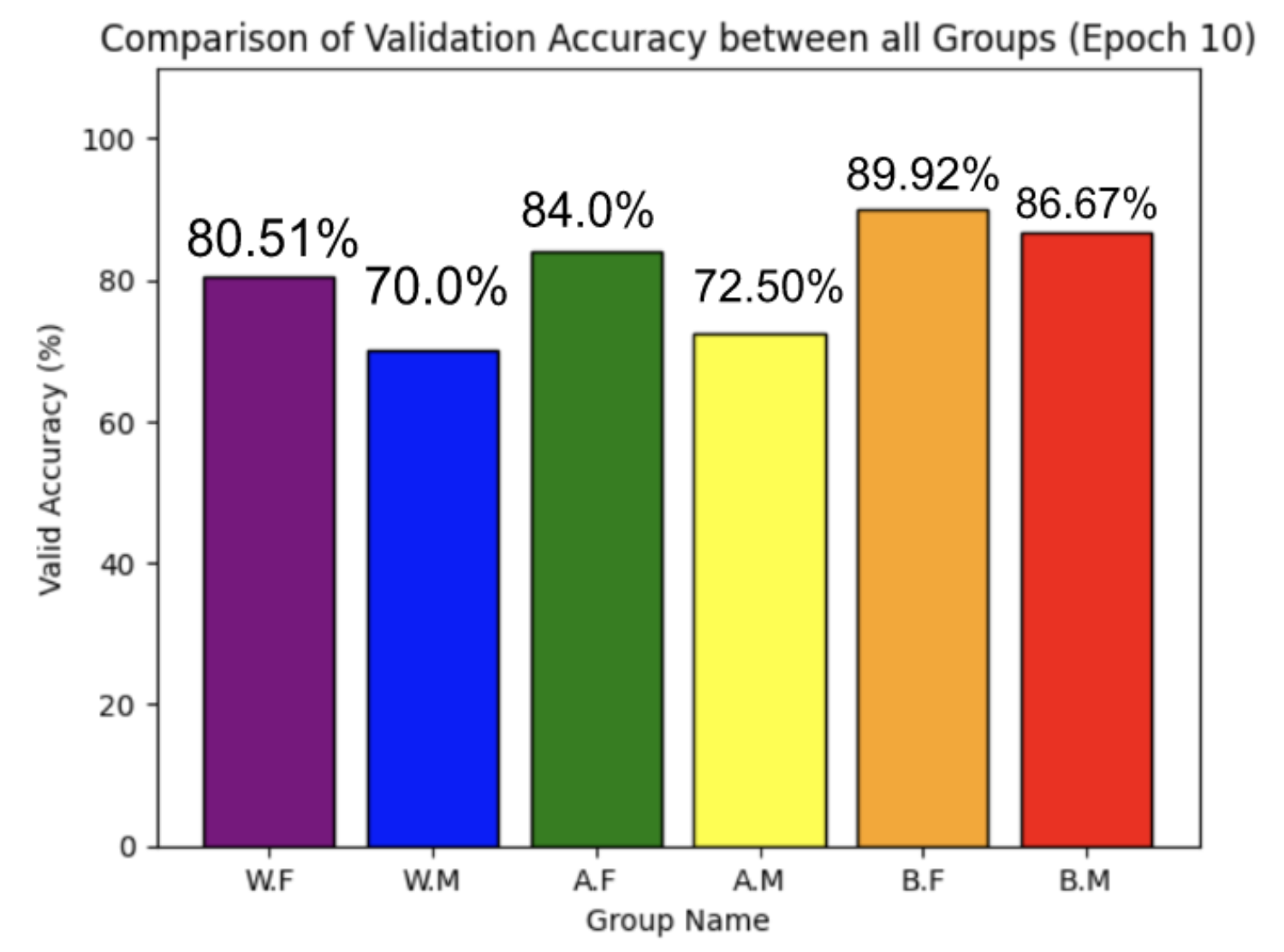
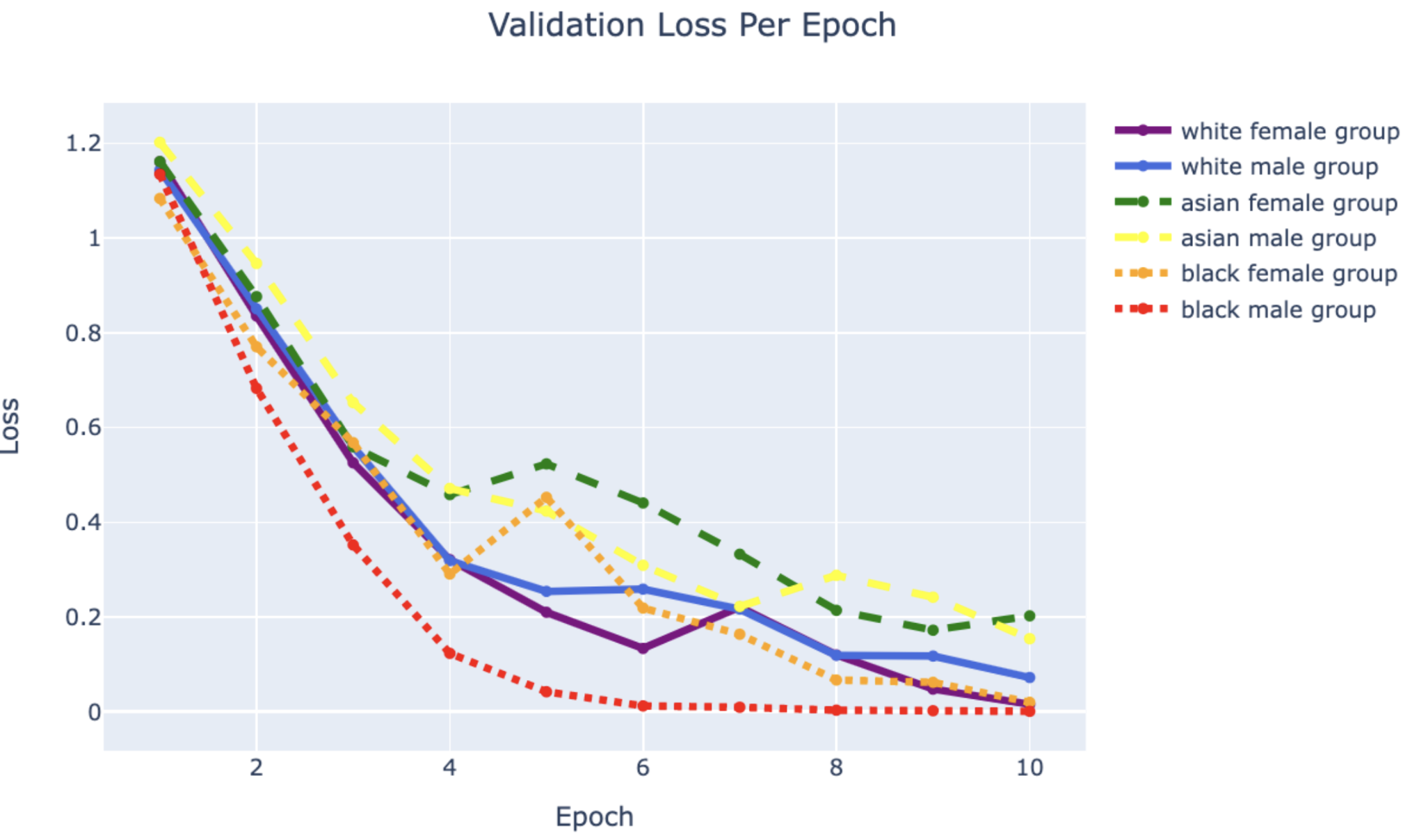
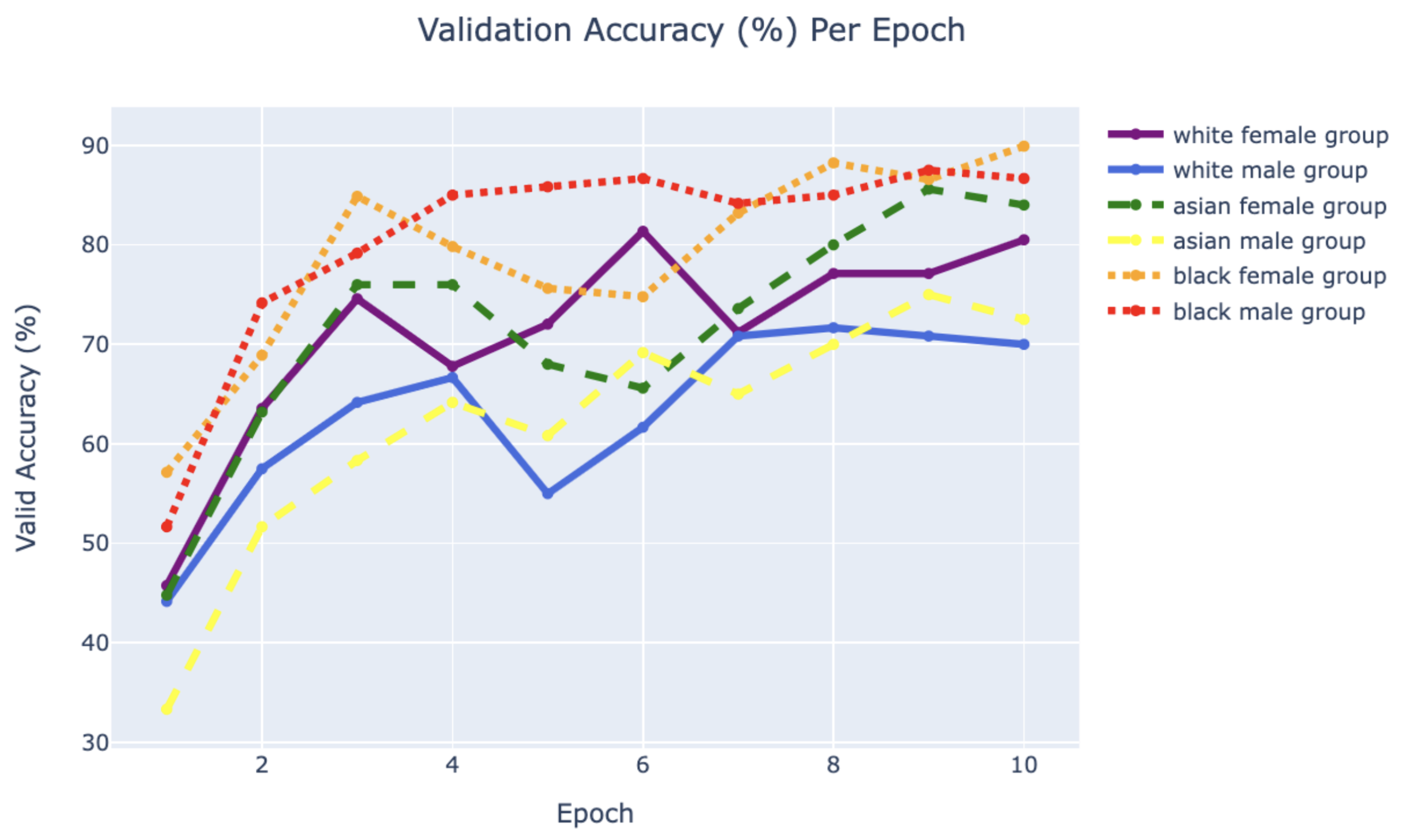
Conclusion
Using PyTorch’s resnet34 function with pre-trained weight set to True, we were able to get a relatively higher validation accuracy (overall ~80% for epoch = 10) on each group of the model with a smaller dataset (360 for training/120 for validating). Also, most groups’ training loss and validation loss consistently decreased in every iteration except for the White Male group and Asian Male group. From our original question, we conclude that our models can detect the correct celebrity with about 80% validation accuracy. However, the results of our models were different than prior research conducted, which was that FRT falsely identified Black and Asian faces 10 to 100 times more often than White faces. Comparing each group, the lower validation accuracy occurred in the White Male group (70% in epoch = 10) and Asian Male group (72.5% for epoch = 10). However, considering our limitations and condition, the results cannot be generalized to apply to the real world since three people in each group cannot simply represent their entire respective gender and racial group.
Future Work
- Would include more people in our model
- Due to our computing resources, model is taking a long time to run
- Would input a new picture into the model that haven't been seen before and test how accurately it recognizes the person
- Wanted to add this to our current model but were limited on time
- Would try to get better pictures using web scraping and validating
- Currently, web crawler randomly picks images based on name input so there's a higher chance of getting lower resolution or wrong image
- Don't have a GPU that can quickly test
- Would add more data with different age groups and appearances
- Even though we were trying to select people with similar appearances for each group, we acknowledge that they cannot represent the group as a whole
- Would add combined gender and race version to see whether model performance is different than that of each group's model
Sources
- https://www.webscrapingapi.com/web-scraping-vs-web-crawling
- https://en.wikipedia.org/wiki/Facial_recognition_system
- https://pceinc.org/wp-content/uploads/2019/11/20190528-Facial-Recognition-Article-3.pdf
- https://www.analyticsinsight.net/what-is-the-importance-of-facial-recognition-in-todays-world/
- http://www.math.le.ac.uk/people/ag153/homepage/MeshkinfamfardGorTyuk2018.pdf
- https://www.flawedfacedata.com/
- https://www.itpro.com/security/privacy/356882/the-pros-and-cons-of-facial-recognition-technology
- https://github.com/ndb796/CNN-based-Celebrity-Classification-AI-Service-Using-Transfer-Learning
- https://www.sciencedirect.com/science/article/pii/S2405959519303455
- https://www.guru99.com/transfer-learning.html#:~:text=What%20is%20Transfer%20Learning%3F